|
|
概述
map-reduce面对低延迟需求的窘境
相对于map-reduce(论文)批处理,我们希望数据计算结果反馈时间能尽量短一些,也就是 “实时一点”;按照惯性,我们可以将map-reduce程序频繁启动,从 一天一次,一小时一次甚至 一分钟一次 来解决延迟问题,但这样首先至少会产生两个问题:
即:
1)大量的额外开销 ;
2)输入文件及其碎片化;
其次是其他很多工程问题,这里不在罗列分析,因为这不是重点,高频次执行map-reduce任务很多问题归根到底是这两点即
1) map-reduce是 为 “高吞吐” 而设计的一个系统,整个设计理念里,就没有考虑 低延迟 这个需求(后续会出map-reduce论文理解)
2)map-reduce的数据,是一份有明确边界的数据 ,即 bounded,即在处理之前数据就已经存在fs上,而我们要进行实时数据统计,需要处理 无边界 unbound 数据,数据实时流入,永无停止的模式;
后续子章节主线
本系列将会以流计算发展及其应用作为主线,来阐述对于流处理系统架构的发展历程,通过对后来出现的系统架构进行概要剖析,看其重点解决了什么类型问题,又有什么难以解决的问题,以及由自身带来的新问题;
其实 流计算 这个术语很是模糊,好似表达计算引擎工作的流式特性,而且很难和微批处理加以区分;
我是很希望使用 “无限数据集合” 来表述 数据的无限流的特性,但由于大众习惯,当我说到流处理,还请大家暂勿纠结表达方式,
只认为是 实时处理无限数据集合 的一种方式 ,而其中实时 暂定理解为处理系统 一直启动运行
流式计算模型的发展起点
雅虎S4系统是早期流计算的尝试,整体架构和map-reduce一脉相承,且兼备流计算topology 雏形,更难得的是,S4系统暴露出来的问题,成为了很多其他系统的起点;
下面我会通过介绍雅虎S4系统来作为流计算综述开端,同时将S4系统问题抛出来,引出其他流计算系统,并阐述其解决方案及其取舍点;
雅虎的尝试 S4 (S4:Distributed Stream Computing Platform )
之于同样孵化于Yahoo的 Hadoop 不同,S4(Simple Scalable Streaming System 论文)开源系统Apache S4 虽然是最早发布开源的分布式流式数据处理系统(之一,其中PE概念借鉴 IBM 的 SPC(stream processing core)),但在市场上却没有占据一席之地,我也没有真正实践运维过,只在论文中学习思考其优缺点;

Figure 1. Word Count Example (S4(Simple Scalable Streaming System 论文) 例子 )
计算过程分析
Figure 1. Word Count Example (最终输出 topK)论文截图
具体PE1~8 数据流转,参看论文 II. DESIGN 部分
S4 规定了抽象的处理对象 即 PE (processing element),每个PE 由四部分组成
1)PE 本身功能,即自定义的 function
2)能够处理的事件类型 types of events
3) 处理事件的键 keyed attribute (非必需,比如上图拓扑入口PE1 的 key 就是null)
4)处理事件的值value
整体job 是为了算出重复次数最多的topK
处理过程:上图 上下可以分为四层 即 PE1, PE2~4, PE5~7, PE8;
第一层(QuoteSplitterPE)PE1 负责 接收外部数据,并拆分单词,并以之为key,计算count,最后 按照key 分发到第二层;
第二层(WordCountPE)PE2~4 负责实时更新 key-count(以为相同key 都会shuffle到到一个PE节点,所以对于具体key来说,就是全局count)
第三层(SortPE)PE5~7 负责topK 排序 ,选出 candidated topK
第四层(MergePE)PE8 负责merge,从上游partial topk 选取出 全局 topk 并输出结果
计算层面问题
问题1)每个 distinct key 就是一个PE,所以第二层会随着输入数据量 产生海量的 PE,而每个PE又要占据内存,造成内存压力(论文给出的解法是 为key 设置TTL 定时清理+内存gc清理,这是个 数据质量和服务可用性的权衡 trade off ,即QoS问题)
问题2)业务开发的逻辑代码,混入了控制分布式数据分发的逻辑,即在第二层和第三层,举例 图中 PE2->PE5 的{key: sortID=2 ,value: word=said count=9} 即(sortID,N)组合,这里的sortID 相对于上下文环境 是不变的,可以理解成下游的 PE的 index,简而言之,(sortID,N)组合中的N越大,则sortID对应的下游PE 要处理的 数据就越多;很显然 业务开发设置sortID 来控制数据分发是不合理的,当需要扩容,则需要从新计算sortID;
架构分析
S4架构和map-reduce框架一脉相承,且更激进,即 S4 是个 无中心,完全对称的架构,没有master 节点,依赖zookeeper(类似chubby)系统注册节点PN(processing node),具体如何分配负载,由各个PN协商决定,而不是master 统一分配;
PN架构
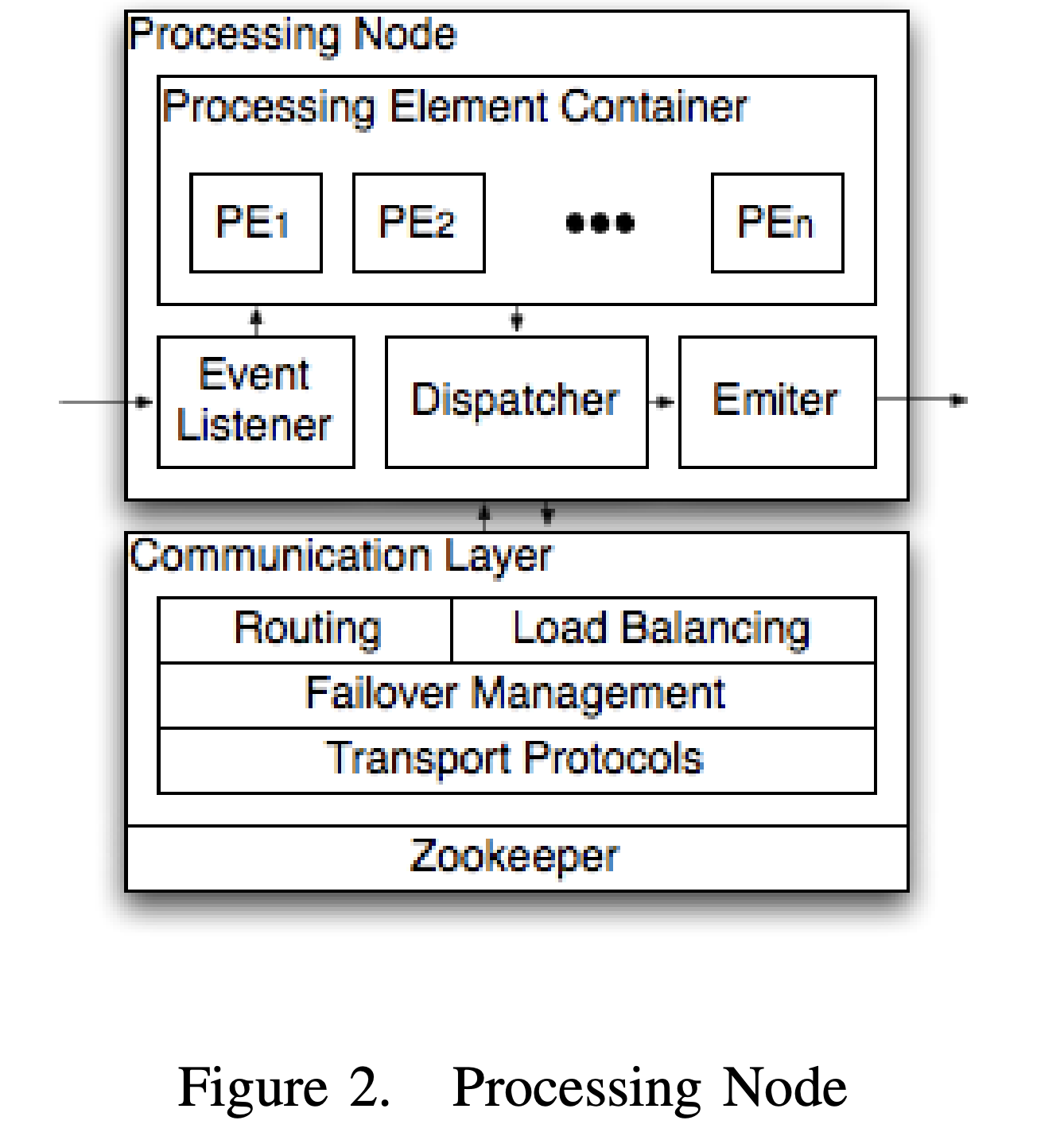

Figure 2. Processing Node (论文截图)
上层: processing element container 是业务处理逻辑模块
event listener 负责监听外部发来的消息,并转给对应的PE
dispatcher 负责接收PN里面PE输出的结果,并确定将消息发给哪些PE
emiter:负责接收dispatcher 发来的消息,并实际对外发送
下层:communication layer 是通信层模块
具体物理路由,即将逻辑PE对应物理机器的处理节点(屏蔽上层逻辑层)
容错回复机制,即节点挂掉,需要在其他节点上恢复 挂掉节点被分配到PE (详情查看论文 D. Communication Layer 部分)
传输协议:TCP/UDP
架构层面问题
一个PE 就是一个对象(kv-pair),造成真是环境是个海量的对象,而不是map-reduce那样只有少数的mapper 和 reducer ,业务逻辑和计算资源 相耦合
问题1)海量对象问题,每一条数据的key 都是一个对象,即使只出现一次,也要占用内存,S4解决方案是 为每个key 设置TTL来定期清除不需要的key(参看论文 B. Processing Elements部分, 个人感觉是基于此架构的折中做法,quality of service balance问题 QoS)
问题2)没有时间窗口概念,很难处理 过去一分钟热搜、一小时热搜 等有时间范围的需求;S4没有设计相关模块,只能由开发者自己在PE代码里面维护实现,想想容错/恢复等问题,大大增加了开发难度和复杂度
问题3)容错处理简单,S4容错 主要是在挂掉节点后,重新拉起一个计算节点,并承担其工作,但是原先节点的 状态信息都会丢失,我们既不知道目前的统计信息是什么,也不知道当前处理到哪些事件(具体分为PE和PN挂掉,恢复详情参看论文),个人观点 S4只能算是保证计算层面的容错,而不是全链路容错
问题4)动态扩容简单,前提假设:系统运行过程中,集群资源不会增加或减少节点;导致如果负载上升过快,S4策略会丢失一些数据(和问题1的 QoS有关)
小结
随着map-reduce这样定时处理数据方式 难以满足业务需求,大数据流式计算开始登上舞台,
S4系统是一个典型的Actor模式,作为流式计算的起点,在今天的视角看有着种种问题,但这些问题也成了后来storm、kafka、millwheel、flink、dataflow等系统等出发点;
个人非常欣赏S4系统流式处理思想,不仅是开启了流式计算帷幕,更是抛出来很多问题,而这些问题解决历程才是更为重要的,基于此我将S4系统介绍放到了 流计算概述里面;
后续我会在其他子章节着重分析后续系统改进点、独特点,即本原要解决的问题,忽略其他非特有的特性,敬请关注; |
|



 发表于 2022-12-1 18:59:06
发表于 2022-12-1 18:59:06